
I was so pleased to be invited to the University of Guelph library by Karen Nicholson and Ali Versluis to give a talk and also to talk with people in the library about user experience and ethnographic research in library and education contexts. This was the last talk that I gave during my November Tour, and I think it came together the most solidly of the four (there’s something to be said for the repetition of experiences in getting things right, note to self). I would also like to thank Chris Gilliard for reading early drafts of this, and helping me clarify some of my argument. Thanks to Jason Davies for the Mary Douglas citation. And credit as well to Andrew Asher, who was my research partner in some of the work I talk about here.
I wrote this talk at my home, in what is now called North Carolina, in the settler-occupied land of the Catawba and Cherokee people. I am a Cajun woman, and my people are a settler people from the Bayou Teche, on Chitimacha land in what is now called Louisiana.
I want to acknowledge here the Attawandaron people on whose traditional territory the University of Guelph stands and offer my respect to the neighboring Anishinaabe, Haudenosaunee and Métis.
************************************
A few years ago, Andrew Asher and I were hired to do a project for an international non-profit that provides electronic resources to libraries in less well resourced countries. The organization was aware that there were low use and high use institutions that they were providing resources for, and wanted to know why that difference was there.
So we interviewed people in Zambia, and in Kyrgyzstan, in places that this organization told us didn’t have connectivity issues. While there might not have been connectivity issues on the university campuses, the practical experience of connectivity was not consistent, as people were not always on campus. As researchers, we encountered this as a problem early on, for example not being able to use Skype for interviews because of connectivity problems. We ended up doing a mix of Skype to call mobile phones, and WhatsApp to conduct interviews in locations where the internet was not reliable for our participants.
Among the things we found out, in the course of our research, was things like in Zambia, people who wanted to have faster internet bought ISP “rabbits,” to gain access off campus. We interviewed a PhD candidate in Engineering who made the point that unless you were on the university network (Eduroam), you could not use university materials (such as library resources). Therefore, using the faster, more reliable (but more expensive) rabbit modems in Zambia locked students and staff out of their institutional resources.
We interviewed a Lecturer in Education with similar issues, even though he was at a “high-use” institution. It wasn’t that the subscriptions weren’t there, or the resources not theoretically available, but that connectivity made those resources less useful, as they were difficult to get to:
“Yes, like I was telling you, either you subscribe to some journal publisher and because of poor connectivity, you may not get access to those services. So it’s basically attributed to poor connectivity. Not that the institution does not have the information, the information could be there but the connectivity limits us from getting access. Cause the system gets to be slow.”
This scholar did point out that doesn’t happen too frequently, so he wasn’t going to complain too much about access. But he highlighted what’s at stake when those failures happen: he can’t do his work.
“Basically, I can just say that is it poor connectivity and when there’s poor connectivity and there’s something that I urgently need to confirm because like when I’m reading a journal article where somebody has cited somebody. There are times when I actually need to read the other article or if it’s a book which they refer to so I’ll probably have to go online to download and if there is not connectivity then that becomes a problem.”
Our research revealed that use of resources (or lack thereof) wasn’t just about connectivity, it was also about culture, and the separation that scholars experienced from the people working in the library. One librarian we spoke to made it clear that the levels of authentication that scholars found burdensome were there on purpose to make sure that only the right people could have access to them. That, however, translated to even the “right people” using those resources less, or not at all, preferring to spend their precious internet time on getting to resources that were more easily accessible, even if not institutionally provided.
In Kyrgyzstan, one scholar assumed that because the physical collection in the library was out of date and inadequate, the electronic resources would be, too.
So, scholars in these two countries, in both “high” and “low” use institutions according to the non-profit, acquired and shared resources via printing, email, and thumb drives more often (and more reliably) than getting resources online via the resources paid for and provided by the organization.
The implications we drew out were as follows:
- Providing materials “online” is not the same as providing “access” when the internet is not a sure thing. Also, having a connection is not the same thing as being connected enough to make using online resources a feasible option. There are many barriers to accessing library materials that are outside of the library’s own systems and infrastructure.
- Scholars find what they need, and what is accessible–if they Google something and it’s closed-access, they move on until they find something they can use. The existence of the materials does not necessarily translate into its use.
- The disconnect of the library from the research workflow of the scholars interviewed here was striking, especially in the context of their awareness for the need for training, and knowledge about how to better navigate useful resources. For example, one Lecturer in Education was at her current institution for 4 years before she knew about electronic resources, and then it wasn’t until she had started her PhD studies at another institution.
And our recommendations were things like: pay attention to physical infrastructure when you offer online resources to institutions. Consider offering resources in digital forms that aren’t just online. Think about facilitating more networking and connections between the people in the library and their surrounding community of scholars. Basically, we told them context matters, and that the non-profit, in providing online resources, was operating as if they were in a vacuum.
Our report had to do with infrastructure, economics, and the lives of the scholars (faculty and students)–The non-profit wanted a problem to fix, and in many ways that was reasonable–it cost money for them to provide these resources, and wanted to avoid wasting resources. What we as researchers presented them with was an exploration of the contexts in which the people they were trying to help (via libraries) were restricted in what was or wasn’t possible.
We did not provide them with a quick-fix solution. In many ways, the questions they wanted to ask were inevitably going to have disappointing answers.
And well, the qualitative work we did wasn’t satisfying, short-term, but I think it’s important nonetheless.
Why was our research unsatisfying? Well, to some extent, the reason is the culture of libraries.
I will point again to the article “Ethnographish” that Andrew and I wrote. We wrote it in a moment, several years into our collective work as anthropologists working in libraries, where we wanted to try to think critically about why the work we were doing looked the way it did. And also why particular kinds of work (especially open-ended exploratory ethnography) was so hard for us to do.
Our argument is: open-ended exploratory research is a hard sell in libraries. We see UX research not just because it’s useful, but because it’s finite, and in particular because it’s proposing to solve specific problems.
“Libraries are notoriously risk averse. This default conservative approach is made worse by anxiety and defensiveness around the role of libraries and pressures to demonstrate value. Within this larger context, where the value of libraries is already under question, open-ended, exploratory ethnographic work can feel risky.“ (Lanclos and Asher 2016)
I think that in positioning themselves as problem-solvers, libraries and library workers are positioning themselves in a tactical way. DeCerteau’s distinction here between kinds of agency (tactical vs. strategy) is useful here, helping us think about the kinds of actors who are allowed choices given their structural position. To what extend to libraries and library workers get to make decisions that aren’t just tactical, not just reactions to situations? How and when do libraries and library workers get to make strategic decisions? Because that has to be more than just responding to demands and solving problems.
A while ago I gave a talk at a CUNY event that advocated for the mixed-methods library. Lots of assessment departments talk about (and some do) both qualitative and quantitative (though I still stand by my impression that a lot of qualitative stuff is UX-style “what is the problem” approaches.). I gave that talk in 2014, and at the time, part of what I was pointing to was the need to get insights that numbers would not give us.
For example, I worked with a university that participated in the Measuring Information Service Outcomes survey. Some of the bar charts we can generate from this data look like this:

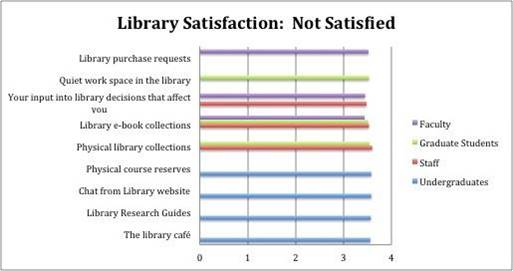
We have all of these numbers, what do they mean? What does “satisfied with the library” mean, anyway? Can graphs like these tell us anything?
In that talk 2014 I actually said “I don’t[ want to get rid of quantitative measures in libraries” but now in 2019 (and actually, way earlier than that) I decided it wasn’t my job to advocate for quantitative anything, and not just because lots of other people are already advocating for that.
Because now in 2019, quantification and problem fixing orientations have landed us with learning analytics, and library analytics, and I think there’s a lot more at stake than “these bar charts don’t tell us enough” (which was bad enough). We have arrived here in part because somewhere along the way arguments accompanied by numbers were interpreted as Most Persuasive (I think we get to thank Economists, as a discipline, for this, given their infiltration into popular news media as commentators).
Being able to categorize people also feels like a constructive action, a first step towards knowing how to “help” people (and categories are certainly central to particular practices in librarianship, and yeah they come with their own troubled history, as anyone who’s read critical work on LOC or Dewey systems will attest).
So let’s think about the impact of categorizing and quantifying academic work, including the work of libraries. Let’s think about what we are doing when we put people into categories, and then make decisions about capability based on that. And yeah. Pop culture quizzes, and even sometimes those management personality tests can be fun.
Where it all ceases to be fun is when decisions get made on your behalf based on the results.
Frameworks and quizzes and diagnostics (what I like to call the “Cosmo Quiz” school of professional development) are often deployed with the result that people decide what “type” they are to explain why they are doing things. Pointing to individual “types” and motivations provides an easy end-run around organizational, structural, cultural circumstances that might also be the reasons for practice. Because then when there are problems, it is up to the individual to “fix it”
What are we doing when we encourage people to diagnose themselves, categorize themselves with these tools? The underlying message is that they are a problem needing to be fixed (fixes to be determined after the results of the questionnaire are in)
The message is that who they are determines how capable they are. The message is that there might be limits on their capabilities, based on who they are
The message is that we need to spend labor determining who people are before we offer them help. Such messages work to limit and contain people, rather than making it easy for people to access the resources they need, and allow themselves to define themselves, for their identity to emerge from their practice, from their own definitions of self.
When UX workers use personas (another way of categorizing people) to frame our testing of websites, we have capitulated to a system that is already disassociated from people, and all their human complexity. The insidious effect of persona-based arguments is to further limit what we think people are likely to do as particular categories. Are first year students going to do research? Do undergraduates need to know about interlibrary lending? Do members of academic staff need to know how to contact a librarians? Why or why not? If we had task-based organizing structures in our websites, it wouldn’t matter who was using them. It would matter far more what they are trying to do.
I am informed in this part of my argument by anthropologist Mary Douglas on How Institutions Think, and in particular that institutions are socially and culturally constructed, and that they themselves structure knowledge and identity. Douglas’ work allows us to think of personas and other kinds of personality test-categories as “patterns of authority”, not just ways of trying to make things clear, but as ways of reifying current structural inequalities, and categories that limit people and their potential. When institutions do the classifying the resulting patterns are authoritative ones, the profiles that suggest plans of action come at the expense of individual agency, and implies that the institutional take on identity is the definitive one that determines future “success.”
What are the connotations of the word “profile?” If you have a “profile” that is something that suggests that people know who you are and are predicting your behavior. We “profile” criminals. We “profile” suspects. People are unjustly “profiled” at border crossings because of the color of their skin, their accent, their dress.
“Profiles” are the bread and butter of what Chris Gillard has called “digital redlining:” ”a set of education policies, investment decisions, and IT practices that actively create and maintain class boundaries through strictures that discriminate against specific groups.“ His work is at “the intersections of algorithmic filtering, broadband access, privacy, and surveillance, and how choices made at these intersections often combine to wall off information and limit opportunities for students.”
“Now, the task is to recognize how digital redlining is integrated into technologies, and especially education technologies, to produce the same kinds of discriminatory results. (Gilliard and Culik 2016) “
Chris gave in his recent Educause talk some examples of what he calls “EdTech WTF moments”
- “Facemetrics tracks kids’ tablet use. Through the camera, patented technologies follow the kids’ eyes and determine if the child is reading, how carefully they are reading, and if they are tired. “You missed some paragraphs,” the application might suggest.
- In a promotional video from BrainCo, Students sit at desks wearing electronic headbands that report EEG data back to a teacher’s dashboard, and that information purports to measure students’ attention levels. The video’s narrator explains: “School administrators can use big data analysis to determine when students are better able to concentrate (Gilliard 2019).”
One problem is that it’s possible to extract quantified behavioural data from systems, in a context (e.g., libraries) where quantified data is perceived as most persuasive
What gets lost in quantification is not just the Why and How (quantification is really good with the What, and occasionally Where), but also the privacy, safety, and dignity of the people whose data you are extracting. This is a “just because you can doesn’t mean you should” situation, especially when we consider our responsibility to people who are already over-surveilled, hypervisible, and structurally vulnerable (i.e., Black, brown, and Indigenous people)
Let’s look at this Guardian article, on student surveillance, and here I’m guided again by Chris Gilliard’s deep dive on this article
Basically, companies like Bark and Gaggle are using school worries about liability around school shootings and student suicides and bullying as a lever by which they gain access to the schools. They sell “security” when what they are actually peddling is “surveillance.”
In this article none of the concerned parties are talking about gun control, or human systems of care that can deal with mental health issues, address discrimination against LGBTQ+ kids, racial bias, and so on. The companies are selling results that are not borne out by the research they hand wave towards. They are counting on people being too scared not to engage with these systems, because they feel helpless
(sound familiar?)
Read the damn thing yourself too, it’s terrifying to me: https://www.theguardian.com/world/2019/oct/22/school-student-surveillance-bark-gaggle
And of course It gets worse–as I was writing this talk a bill was introduced by US Republican senators to make school engagement with this tech (and these tech companies) MANDATORY.
Thanks to Chris Gilliard and his work, I am also aware of Simone Browne’s work Dark Matters: on the Surveillance of Blackness. In this book, she writes a black feminist, critical race studies informed take on surveillance studies. She points particularly to the history of surveillance technology as being one that emerges from the white supremacist need to police black people, black bodies. Her examples include enslavement trading practices of the 1800s, the tracking and control of enslaved people via paper permits and laws about carrying lanterns after dark, and she makes it clear that this history is relevant to current discussions of how we make people visible, in what circumstances, and why. We cannot disentangle race and inequality from our discussions of these technologies, nor should we try to in a quest for “neutrality” or “objectivity.”
The surveilling gaze is institutionally white, and furthermore, as Browne demonstrates in her book, that the technologies and practices of surveillance have a deep history in the colonization and enslavement of black and indigenous people. The history of current surveillance practices involves the production and policing of racialized categories of people, in particular blackness and black people, so that they can be controlled and exploited.
We need to think too about the racist context in which data is generated and collected, as in the case with health care data used to generate algorithms intended to guide health care decisions. In Ruha Benjamin’s perspective piece in that same issue of Science, she notes that researchers “found that because the tool was designed to predict the cost of care as a proxy for health needs, Black patients with the same risk score as White patients tend to be much sicker, because providers spend much less on their care overall. “
While surveillance and tracking are clearly forms of control, and the use of algorithms is a problem, their use is often framed as care (again, see the people interviewed and quoted in the Guardian article, and this is an argument I hear in library contexts too, “we need the data to care for students and faculty.”)
Insisting that people have to participate in systems that harvest their data to have access to education or health care is a kind of predatory inclusion.
“Predatory inclusion refers to a process whereby members of a marginalized group are provided with access to a good, service, or opportunity from which they have historically been excluded but under conditions that jeopardize the benefits of access. Indeed, processes of predatory inclusion are often presented as providing marginalized individuals with opportunities for social and economic progress. In the long term, however, predatory inclusion reproduces inequality and insecurity for some while allowing already dominant social actors to derive significant profits (Seamster 2017).”
When people become aware that they are under surveillance, there can be a ”chilling effect” where they do not engage with the system at all. This is refusal, not engaging with the system because of wariness of what might happen if they do. We need to consider carefully the disparate effect some of these methods of surveillance may have on trans students, undocumented students, and other vulnerable populations.
Our role as educators, as workers within education, should be to remove barriers for our students and faculty (and ourselves), not give them more.
We also need to think critically about whether the systems we are extracting data from accurately reflect the behaviors we are interested in. For example, borrowing histories, swipe card activity records, and attendance tracking are all proxies for behaviors, not direct observations, and not necessarily accurate representations of behaviors (even as they might seem precise, and make us feel good about our precision biases).
And if you are worried about “How will we know…X” please do not assume that these systems are the only way. Because the vendors selling these systems that collect this problematic data want you to THINK that it’s the best and only way to find things out. But that is not true.
The fight against quantification, pigeonholing, surveillance and tracking should include qualitative research engagement –like the stuff that I do, like the stuff I try to write about and train people to do, and encourage them to try–engagement with the people from whom we want to learn, and with whom we want to work. I would even suggest that the lack of “scalability” of qualitative methods is a benefit, if what we want is to be able to push back against surveillance and automated systems.
It’s about more than being able to be strategic on behalf of libraries and library workers, but also being able to create space for students and faculty to be strategic, to exercise power and agency in a context that increasingly wants to remove that, and put people at the mercy of algorithms. This is particularly dangerous for already vulnerable people–Black and brown, Indigenous, women, LGBTQ+ people. Exploratory ethnographic approaches, engaging with people as people (not as data points) gives us not just more access to the whys and hows of what they are doing, but can work to connect us with them, to build relationships, so that we don’t have to wonder for long “why are they doing that.” Then we won’t have to listen to people who rely on machines and their broken proxies for human behavior and motivations.
Further Reading and Resources
LIBRARY TRENDS, Vol. 68, No. 1, 2019 (“Learning Analytics and the Academic Library: Critical Questions about Real and Possible Futures,” edited by Kyle M. L. Jones), © 2019 The Board of Trustees, University of Illinois
Benjamin, Ruha, “Assessing risk, automating racism,” Science 25 Oct 2019: Vol. 366, Issue 6464, pp. 421-422. DOI: 10.1126/science.aaz3873 https://science.sciencemag.org/content/366/6464/421.full
Browne, Simone. Dark matters: On the surveillance of blackness. Duke University Press, 2015.
de Certeau, Michel, and Steven Rendall. The Practice of Everyday Life. University of California Press, 2011.
Douglas, Mary. How institutions think. Syracuse University Press, 1986.
Gilliard, Chris “Digital Redlining” featured session, EDUCAUSE conference, Chicago, October 16, 2019. https://events.educause.edu/annual-conference/2019/agenda/digital-redlining
Gilliard, Chris and Hugh Culik “Digital Redlining, Access and Privacy” Privacy Blog, Common Sense Education, May 24, 2016, https://www.commonsense.org/education/privacy/blog/digital-redlining-access-privacy
Lanclos, Donna, and Andrew D. Asher. “‘Ethnographish’: The State of the Ethnography in Libraries.” Weave: Journal of Library User Experience 1.5 (2016). https://quod.lib.umich.edu/w/weave/12535642.0001.503?view=text;rgn=main
Obermeyer, Ziad, and Sendhil Mullainathan. “Dissecting Racial Bias in an Algorithm that Guides Health Decisions for 70 Million People.” Proceedings of the Conference on Fairness, Accountability, and Transparency. ACM, 2019. https://science.sciencemag.org/content/366/6464/447
Safiya Umoja Noble. Algorithms of Oppression: How search engines reinforce racism. NYU Press, 2018.
Seamster, Louise, and Raphaël Charron-Chénier. “Predatory inclusion and education debt: Rethinking the racial wealth gap.” Social Currents 4.3 (2017): 199-207. https://journals.sagepub.com/doi/abs/10.1177/2329496516686620?journalCode=scua
Watters, Audrey. (2014) “Ed-tech’s Monsters” Hack education, Sept 3, http://hackeducation.com/2014/09/03/monsters-altc2014
